Commafree Codes: Backtracking & Data Structures 中文
Introduction
In the previous post we generated all prime words for m=3, n=4 — 18 cyclic classes in total. This post covers how to select the largest commafree subset from those 18 classes.
Recall: picking a codeword also eliminates its cyclic shifts. For example, after selecting 0001, the sequence 00010001 contains the interior substrings 0010, 0100, and 1000, so those cannot be codewords. For each cyclic class we must choose at most one representative to include.
Brute-Force Search
The simplest approach tries every cyclic shift of every class and checks the commafree condition:
def pick_code(codes):
if len(codes) == 0:
if len(result) > max_result:
max_result = result
return
for code in codes:
for shift in get_shifts(code):
if is_commafree(result + [shift]):
result.append(shift)
pick_code(codes - {code})
result.pop()
With a good selection order the search converges quickly. For example:
- Choose 0001 first
- Choose 0011 second
- The next five choices — 0002, 0021, 0111, 0211, 2111 — are all forced
Those five moves in step 3 are not guesses; they are the only legal options once the first two choices eliminate all other cyclic shifts. Detecting and exploiting forced moves is a key pruning technique.
Dynamic Variable Ordering
Naïve backtracking processes the 18 classes in a fixed order (x0001, x0002, x0011, …). This is suboptimal: different branches of the search tree may have very different constraint patterns. A better strategy is dynamic ordering — at each step, branch on the class with the fewest remaining legal candidates. This finds dead ends earlier and avoids exploring large irrelevant subtrees. For instance, after setting x0001=0001, branching on x0012 (only 2 options left) is better than x0122 (still 3 options).
Optimized Data Structures
Sparse Set
To efficiently track and update the search state, we use a sparse set. It stores a dynamic subset of {0, …, M−1} using two contiguous memory regions: a forward array starting at HEAD (the active list) and an inverse array starting at IHEAD (recording each element’s position). TAIL points one past the last active element.
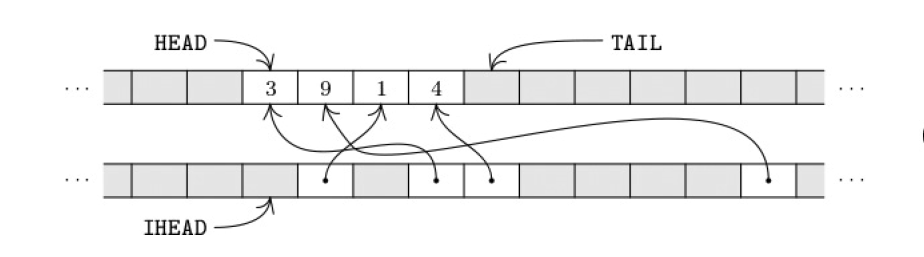
Insert
def add_to_set(mem, head, tail, ihead, x):
if head <= mem[ihead + x] < tail:
return
mem[tail] = x
mem[ihead + x] = tail
tail += 1
Delete
To delete element 9: swap it with MEM[TAIL−1], update the inverse pointer, then decrement TAIL.
def remove_from_set(mem, head, tail, ihead, x):
if not (head <= mem[ihead + x] < tail):
return
if head == tail:
return
p = mem[ihead + x] # position of the element to delete
tail -= 1
if p != tail:
y = mem[tail]
mem[tail], mem[p] = mem[p], y # swap with last element
mem[ihead + x], mem[ihead + y] = tail, p # update inverse pointers
Red / Blue / Green States
When m=4 there are 60 cyclic classes — the search space grows dramatically. Algorithm C colors every 4-letter word with one of three states:
- Green: selected as a tentative codeword in the current branch
- Red: ruled out (incompatible with existing green words, or already tried)
- Blue: undecided — may become green or red
All words start blue, except the \(m^2\) periodic words which are permanently red.
We define \(\alpha(x)\) as the base-m integer value of word x: for example \(\alpha(0102) = (0102)_3 = 0 \cdot 27 + 1 \cdot 9 + 0 \cdot 3 + 2 = 11\). The color of word x is stored in MEM[α(x)].
Seven sparse sets track the blue words by prefix, suffix, and cycle class:
- P1(x), P2(x), P3(x): blue words matching \(x_1{\star}{\star}{\star}\), \(x_1x_2{\star}{\star}\), \(x_1x_2x_3{\star}\)
- S1(x), S2(x), S3(x): blue words matching \({\star}{\star}{\star}x_4\), \({\star}{\star}x_3x_4\), \({\star}x_2x_3x_4\)
- CL(x): blue words in the cycle class \(\{x_1x_2x_3x_4,\ x_2x_3x_4x_1,\ x_3x_4x_1x_2,\ x_4x_1x_2x_3\}\)
Each set has three arrays: the forward list, the inverse list, and a stored TAIL pointer for backtracking.
Closed Lists
Once a word becomes green, any list containing it is permanently “blocked” in that direction and no longer needs updating. Algorithm C marks such lists as closed by setting TAIL = HEAD − 1 (a sentinel value). Subsequent list updates skip closed lists entirely, eliminating most maintenance work.
Poison List
Selecting green word \(x_1x_2x_3x_4\) creates three commafree constraints between suffix patterns and prefix patterns:
\[(\star x_1 x_2 x_3,\ x_4 \star \star \star),\quad (\star\star x_1 x_2,\ x_3 x_4 \star\star),\quad (\star\star\star x_1,\ x_2 x_3 x_4 \star)\]Each constraint says the left-side list and right-side list cannot both contain a green word. These constraints form the poison list. After each choice, the algorithm scans the poison list:
- Both sides green → dead end, backtrack immediately
- One side green, other side has blue words → color those blue words red
- One side empty → constraint can never fire, remove it from the poison list
For example, when 0010 becomes green, the first constraint (*001, 0***) immediately makes 1001 red (since 0*** already has the green word 0010).
UNDO Stack — Reversible Memory
All changes to MEM go through a single UNDO stack:
store(a, v): push (a, MEM[a]) onto UNDO stack, then set MEM[a] ← v
unstore(u0): pop until stack depth reaches u0, restoring each MEM[a]
When backtracking from a level, one call to unstore(u0) restores MEM to the state before that level was entered. The cost is proportional to the number of changes made in that level, not to the total size of MEM. An optional optimization: stamp each address so that only the first write to a given address in a given round is pushed — later writes to the same address just overwrite directly.
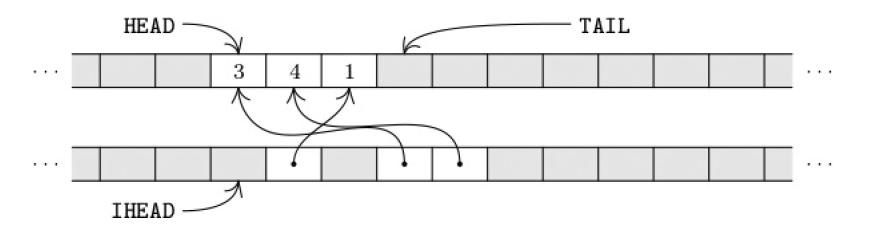
Example

This diagram shows MEM for m=2 after choosing 0010 as green (level 2). Words 0001 and 1001 are colored red; P1(0010) and six other lists are closed; the poison list reduces to the single constraint (**00, 10**).
Results for m=4
With m=4 there are 60 cyclic classes (upper bound 60 codewords). Knuth’s Algorithm C established:
| Goal g | Exists? | Cost |
|---|---|---|
| 60 | No | 13 megamems |
| 59 | No | 177 megamems |
| 58 | No | 2,380 megamems |
| 57 | 1,152 solutions | ~22,800 megamems |
Throughout the search the UNDO stack never exceeds depth 2804, and the poison list never holds more than 12 entries at once — a testament to how compact these data structures are.
Summary
This post covered the key ingredients for building commafree codes efficiently: sparse sets, the red/blue/green three-state coloring, seven prefix/suffix/cycle lists, closed-list optimization, poison-list lookahead, and the UNDO stack for reversible memory. Together these form the backbone of Knuth’s Algorithm C.

